
딥러닝을 이용한 자연어 처리 학습을 마치며...최신 연구동향을 추가로 학습하는게 필요하다는 생각을 하게됩니다.
하지만 모든 연구를 관통하는 핵심 사상이 있다면 무엇이라고 할 수 있을까요?
자연어 처리 연구를 앞으로 어떻게 진행이 될까요? 자연어 처리 연구의 선구자들은 누가 있을까요?
어떤 학제간의 연구가 이루어져야 할까요?
자연어 처리(NLP, Natural Language Processing)란 컴퓨터가 인간의 일상 언어(자연어)를 이해하고, 해석하고, 생성할 수 있도록 하는 인공지능(AI) 기술로, 머신러닝과 딥러닝 기술을 기반으로 텍스트와 음성 데이터를 분석하여 의미를 추출하고, 정보 검색, 번역, 감정 분석 등 다양한 언어 기반 작업을 수행합니다. 이는 시리(Siri), 빅스비 같은 음성 비서, 자동 번역, 이메일 스팸 필터, 검색 엔진 등에 광범위하게 활용됩니다.
자연어처리 기술 개발의 역사
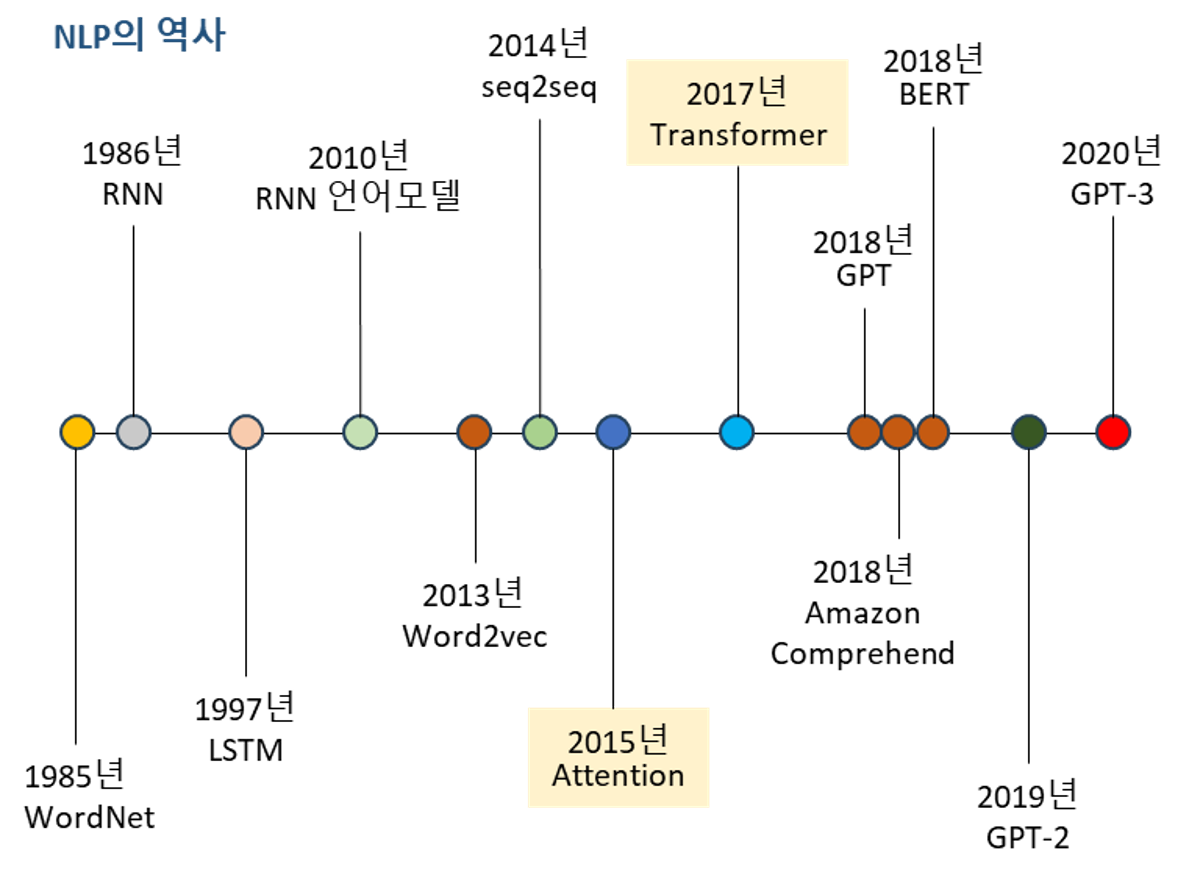
자연어 처리 기술은 지금으로부터 무려 70여년 전인 1946년으로 거슬러 올라간다고 해요. 미국의 과학자 워런 웨이버(Warren Weaver)는 2차 세계대전 때 적군의 암호문을 번역해 정보를 알아내기 위한 용도로 기계번역(MT, Machine Translation)이라는 기술을 개발해냈지요. 그 후 MT는 암호문 분석뿐만 아니라 언어 번역에도 확장돼 연구되기 시작했고, 1970년부터는 자연어 생성에 관한 연구도 진행되었답니다. 인터넷을 제약없이 사용할 수 있게 된 1990년대를 기점으로 자연어로 된 문서를 웹상에 등록하고 자유롭게 검색 및 저장 가능한 환경이 형성되어 방대한 데이터가 쌓이게 되었고, 주어진 데이터로 알고리즘을 만들어내는 기계학습(Machine Learning)기술이 등장함에 따라 자연스럽게 컴퓨터의 자연어 처리 학습을 도와주고 빠르게 기술 수준이 고도화되는 효과를 낳게 되었어요.1990년대 이후에는 말뭉치 데이터를 활용하는 기계학습 기반 및 통계적 자연어 처리 기법이 주류를 이뤘는데, 2018년 구글이 교육 없이 양방향으로 사전학습 하는 인공지능(AI) 언어모델 ‘BERT’(이하 버트, Bidirectional Encoder Representations from Transformers)를 공개하여 시장에 큰 변화를 일으켰지요. 교육이 없다는 것은 특별한 프로그램에 따르지 않고 웹상에 있는 보통의 텍스트 데이터만 가지고도 훈련이 가능하다는 의미로, 어텐션 매커니즘(attention mechanism)만을 활용해 자연어를 처리하는 방식인 ‘셀프 어텐션(self-attention)’ 방식을 채택하고 있어요. 어텐션 매커니즘은 문장 전체의 중요성을 모두 분석하는 대신 중요한 부분만을집중(attention)해 문장을 분석하는 방식으로,더 적은 연산으로도 효율적으로 문장을 이해할 수 있다는 장점이 있고, 빠르고 쉽게 성능을 향상할 수 있다는 강점을 가지고 있다는 것이지요.
Open AI에서 2020년 공개한 GPT-3(Generative Pre-Training)은 양방향으로 자연어를 분석하는 버트와 달리 한 방향으로 분석하는 단방향 모델이에요. 테슬라 최고경영자(CEO)로 더 유명한 일론 머스크는 2015년 인류에게 이익을 주는 것을 목표로 인공지능 회사 Open AI를 설립하고 인공지능의 정보를 오픈소스화 하였어요. 이 회사가 개발한 GPT-3은 상대적으로 자연어를 이해하는 성능은 부족하지만 차례로 문장을 만들어나갈 수 있어 자연어 생성에 적합하며, 자연어 이해와 연관되면서도 보다 구현하기 어려운 상위 기술이라고 해요. 실제로 GPT-3 모델은 4,990억개데이터셋중에서가중치샘플링해서 3,000억(300B)개로구성된데이터셋으로사전학습을받았으며, 1,750억개(175Billion) 매개변수로딥러닝의한계까지추진돼미세한조정없이여러자연어처리벤치마크에서최첨단성능을달성했답니다.
자연어 처리 기술 분야와 시장성
자연어 처리는 컴퓨터와 사람의 언어 사이의 상호 작용에 대해 연구하는 AI의 주요 분야 중 하나로 손꼽히고 있어요. 머신러닝을 통해 인간의 언어를 공부한 AI가 사람의 말이나 문자를 이해하고 다양한 업무를 처리하는 거죠. 그래서 최근 인공지능(AI) 분야에서 자연어처리관련 시장이 급격히 커지고 있고, AI 스피커, 챗봇 서비스, 전화 상담 등 다양한 곳에서 자연어 처리 기술을 활용하고 있지요. 사람의 언어를 이해하는 기술인 자연어 이해 부분, 기계의 작문 기술로 표현할 수 있는 자연어 생성, 음성인식기술, 기계번역(MT, Machine Translation), 오타 검열 등이 자연어 처리 기술이 활발하게 쓰이고 있는 분야라고 해요.오늘날 자연어 처리 기술의 시장성은 코로나 펜데믹 발생에 따라 빠르게 확산된 비대면 환경으로 더욱 더 빠르게 커지고 있어요. 마켓앤마켓(MarketsandMarkets)이 발간한 '2026년까지 전 세계 자연어 처리 시장 전망 (Natural Language Processing Market - Global Forecast to 2026)' 보고서에 따르면 전 세계 자연어 처리 시장 규모가 2020년 116억 달러(약 16조 5천억원)에서 2026년이 되면 351억 달러(약 49조 9천억원)로 연평균 20.3% 씩 성장할 거라고 전망했답니다. 우리가 잘 알고 있는 IBM, 마이크로소프트(Microsoft), 구글(Google), AWS(Amazon Web Service), 페이스북(Facebook), 애플(Apple), 3M, 인텔(Intel) 등이자연어 처리 시장을 이끄는 주요 업체로 손꼽히고 있지요.
한국의 자연어처리 활용 서비스
여태껏 미국을 중심으로 한 자연어 처리 기술의 탄생과 발전, 주요 회사들을 살펴보았는데요 그럼 한국의 자연어 처리 기술과 서비스는 어디까지 왔을까요? 역대 최고의 자연어 처리 기반 AI로 평가받는 Open AI의 GPT-3 API(프로그램 언어 형식)를 분석해보면 97%가 영어이고 한국어는 0.01%에 불과하다고 해요. 애초에 글로벌 인터넷상 한국어 데이터가 0.6%밖에 되지 않기 때문이죠. 하지만 국내 대기업과 스타트업에서 앞다투어 자연어 처리 기술과 관련된 서비스 개발에 온힘을 기울이고 있답니다.대표적으로 네이버가 2021년 처음 공개한 초거대 AI인 하이퍼클로바’는 AI 모델의 크기와 성능을 보여주는 매개 변수(파라미터)가 2040억 개로 오픈AI의 ‘GPT-3(1750억 개)’를 넘어선다고 해요. 하이퍼클로바는 GPT-3보다 한국어 데이터를 6500배 이상 학습했고, 학습 데이터 중 한국어 비중이 97%에 달해 세계에서 가장 큰 한국어 거대 언어모델을 구축했지요.
카카오는 ‘카카오디벨로퍼스’를 통해 자체 개발한 한국어 특화 초거대 AI 언어 모델 ‘KoGPT’를 오픈 API(응용프로그램 인터페이스)로 공개했는데, 'KoGPT API'는이용자가 입력한 한국어를 사전적, 문맥적으로 이해하고 이용자 의도에 적합한 문장을 생성하는 기능을 제공하는 도구에요. 맥락과 의도에 따라 문장을 생성해 상품 소개글 작성, 감정 분석, 기계 독해, 기계 번역 등 높은 수준의 언어 과제를 해결하고 다양한 분야에서 활용할 수 있다고 하네요.카카오의 AI 전문 자회사 카카오브레인 출신의 NLP 엔지니어들이 주축으로 2021년 설립한 튜닙은 지난 8월에 내놓은 GPT-3’에 기반으로 영어 여행 챗봇 ‘블루니’를 개발해서 공개하였고, 지난 10월에는 반려견 캐릭터 챗봇 코코와 마스의 시험 버전을 출시했어요. 각각 다른 성격을 가진 강아지 캐릭터의 AI 챗봇으로 이용자와 정서적 교감이 가능한 것이 특징인데 간식 주기, 산책하기 등 실제 반려견 같은 활동과 N행시 등 여러 게임을 함께할 수 있지요.
요새 장안의 화제인 서비스로는 지난 4월 설립된 에듀테크 스타트업 '뤼튼테크놀로지스가 개발한 AI 기반 문서작성 도구 '뤼튼(Wrtn)'을 빼먹을 수가 없는데요, '뤼튼'은 문서작성 전부터 작성하는 과정, 작성 후 피드백까지 모든 과정을 지원한다고 해요. 연구활동, 자기소개서, 에세이 등 작성하고자 하는 양식을 설정하면 뤼튼은 가장 적합한 템플릿과 프레임워크를 제공해 독창적인 생각을 짜임새 있는 글로 표현할 수 있도록 돕죠.작성 중인 내용에 실시간으로 반응하면서 검증된 자료들을 추천하며, 글을 완성한 뒤에는 글의 취약점을 분석해주고 피드백을 해준다니 라떼 빨간펜 선생님을 뛰어넘는 Z세대 뤼튼 선생님이네요!
자연어처리 활용 기술의 미래
그렇다면 자연어 처리 활용 기술의 미래는 무엇일까요? 자연어처리 기술을 사용한 기계번역기술이 고도화된다면 지금보다 더 많은 세계인들이 자국 콘텐츠 처럼 한국 드라마와 K-pop, 영화, 서적등을 자연스럽게 보고 즐길 수 있겠죠! 음성인식기술 또한 고도화된다면 컴퓨터, 핸드폰, 키오스크, 자동차 등의 입력하거나 버튼을 눌러 작업을 명령하는 지금의 방식에서 벗어나 기계와 인간이 직접적 대화를 할 거에요. 기계가 인간이 원하는 작업을 수행하고, 자연스럽게 상호작용하면서 말에 담겨있는 인간의 의도까지 파악해 때로는 친구처럼, 때로는 가족처럼 인간과 함께 울고 웃을 수 있을 거에요.
- The Science Times, ‘자연어처리 기술, 사람 수준 뛰어넘었다’(2020.10.27)
- 동아사이언스, ‘[프리미엄 리포트] 현존 최고의 자연어처리 인공지능 선발대회’(2021.01.09)
- 인공지능신문, ‘[이슈] OpenAI, 혁신적인 AI 자연어처리(NLP) 모델 'GPT-3' 공개’(2020.06.03)
- 한경 Geeks, ‘사람 같은 AI 만드는 자연어처리 기술…어떤 스타트업이 이끄나(2022.10.25)
- “Commercial Application of Natural Language Processing” by Kenneth W.Church, Lisa F.Rau(1995.11)
- 비즈한국, ‘인공지능이 기사를 써봐야 얼마나 잘 쓴다고…’(2022.10.28)
- The Science Times, ‘자연어처리, 미래 국가 경쟁력 좌우(2012.10.9)
[NLP] 자연어처리 딥러닝 모델 변천과정 (RNN, LSTM, Seq2Seq, Attention, Transformer)
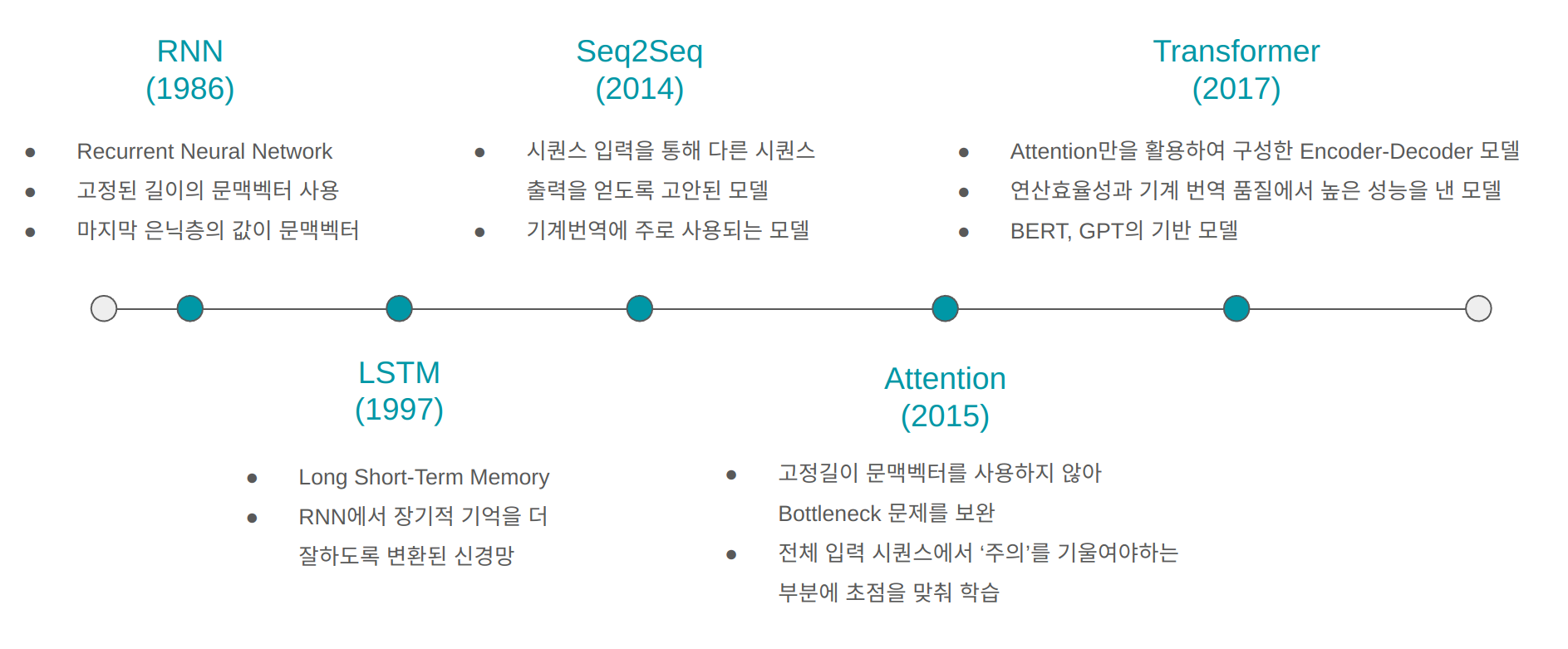
1. RNN (1986)
RNN은 시퀀스 데이터를 학습시키기 위해 제안된 신경망 모델로 RNN 기법이 처음으로 제안된 논문은 아래와 같다. 이 논문을 기틀로 RNN 연산을 거치는 신경망모델에 대한 수많은 연구가 수행되었다.
2. LSTM (1997)
LSTM은 RNN의 은닉층에서 계산되는 연산을 변형시켜 장기적 기억을 더 잘하도록 고안된 신경망 모델이다. 처음으로 LSTM 매커니즘이 제안된 논문은 아래와 같다.
최종적으로 자리잡은 RNN과 LSTM에 대한 개념은 아래의 논문에서 확인할 수 있다.
- Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network
- 정리글 1) RNN(Recurrent Neural Network) 순환신경망 공부하기 2) LSTM(Long Short-Term Memory) 신경망 모델 공부하기
3. Seq2Seq (2014)
시퀀스 데이터에 대한 입출력을 처리할 수 없는 DNN의 한계를 보완하기 위해 고안된 모델로 LSTM 연산을 여러 layer로 쌓은 Encoder-Decoder 구조이다. 이는 기계 번역에서 성능 향상의 효과로 인기를 얻게되었다.
하지만 Seq2Seq 모델까지는 데이터마다 다른 길이의 입력값에 대해 고정된 길이의 문맥벡터를 출력하는 한계점이 있었다. 이러한 이유로 정보 손실과 비효율적인 연산이 이루어지는 Bottleneck문제가 발생했다.
4. Attention (2015)
Attention은 기존의 고정길이 문맥벡터를 사용하던 것으로 인한 Bottleneck문제를 해결하기 위해 고안되었다.
위의 논문에서는 Encoder로 bidirectional RNN을 사용하여 순서와 문맥정보를 담고있는 문맥벡터(context vector)를 출력하고, Decoder에서만 Attention 기법을 제안하고, 적용하였다.
Attention 기법을 간단하게 설명하면, 전체 입력 시퀀스에 대해 어떤 정보에 가장 주의를 기울일 것인지 판단하여, 다음 시퀀스를 예측하는데 활용하는 방식이다. 따라서, Attention기법을 사용한 Decoder 구조에서는 아래의 세가지를 활용하여 다음 시퀀스를 예측한다.
- 전체 입력 시퀀스에 대한 hidden states(은닉값)에 가중치를 적용한 문맥벡터 (ci)
- 이전 step때 decoder에서 출력한 문맥벡터 (si−1)
- 이전 step때 decoder에서 출력한 단어벡터 (yi−1)
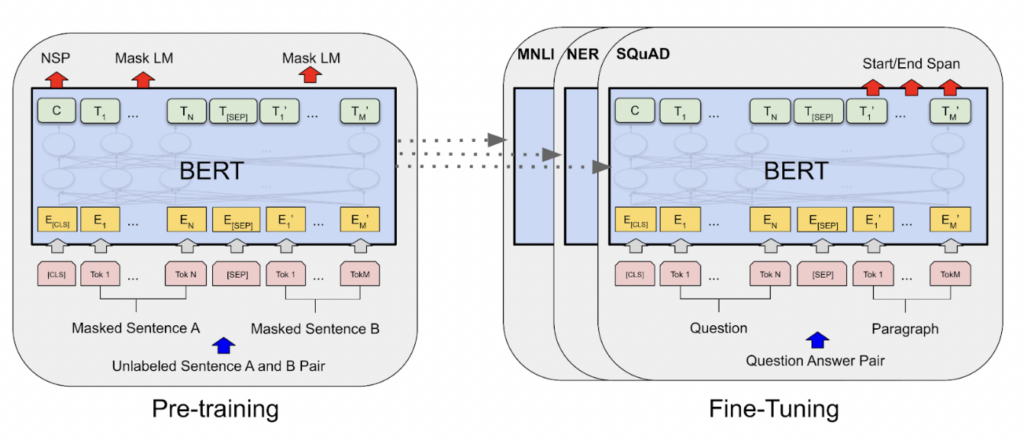
5. Transformer (2017)
Transformer는 기존의 RNN,CNN과 같은 core machanism을 쓰지않고, 오직 Attention 방식만을 활용한 Encoder-Decoder 구조의 신경망 모델이다.
Attention 매커니즘에서는 전통적으로 수행하던, 시퀀스를 순차적으로 입력하는 방식을 사용하지 않기 때문에 데이터의 순서정보를 입력해주기 위해서 Positional Encoding이라는 기법을 추가적으로 수행해줘야 한다. 이 방식을 통해 인코더에 전체 시퀀스를 하나의 임베딩 행렬로 입력하는 방식으로 병렬적인 계산이 가능하게하여 연산 효율성을 높혔다. 결과적으로 기존의 RNN, CNN기반의 모델보다 Attention만 사용하여 학습했을 때의 성능이 훨씬 높아 지금까지 큰 인기를 얻고 있다. 이후에 나온 유명한 BERT와 최근까지도 계속 발전되고 있는 GPT, LLM 모델도 모두 Transformer를 활용한 모델이다.
comment