
[5. 신경망 기계 번역] 관련 질문입니다.
Q. Vocabulary 크기는 문제마다 다르게 설정해야하나요?
Vocabulary 크기를 정해야 되잖아요. 굉장히 너무 크면 이제 ... 그건 이제 아까 말씀하셨을때 트레인 셋에서 그 노이즈를 필터링하는 문제마다 다르다고 말씀하셨는데 이것도 이제 문제마다 다르다고 이해하면...?
A.
(조경현 교수님 답변입니다.)
Vocabulary 사이즈 정하는거요...예 그게 사실 굉장히 중요한 문젠데요, 잠깐만 가보죠...
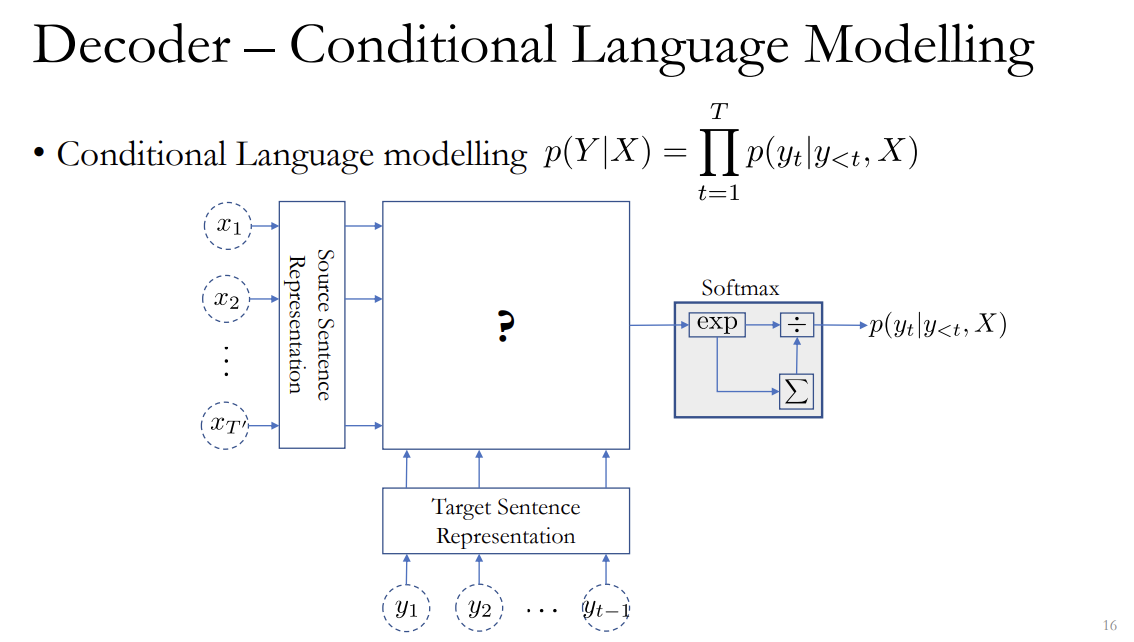
(<lecture4 - machine translation.pdf>의 16쪽 장표를 보면서 설명)
이제 Vocabulary 사이즈라는게 그니까 크면 클수록 Softmax function을 계산을 하는게 점점 비싸집니다.
왜냐면 이게 전부 계산을 하고 나서 더하고 다 나눠주는 프로세스가 필요하니까요. 그래서 이제 Vocabulary 사이즈를 적당히 되는데...그래서 제가 잠깐만 뒤쪽으로 가서 보여드리면은...
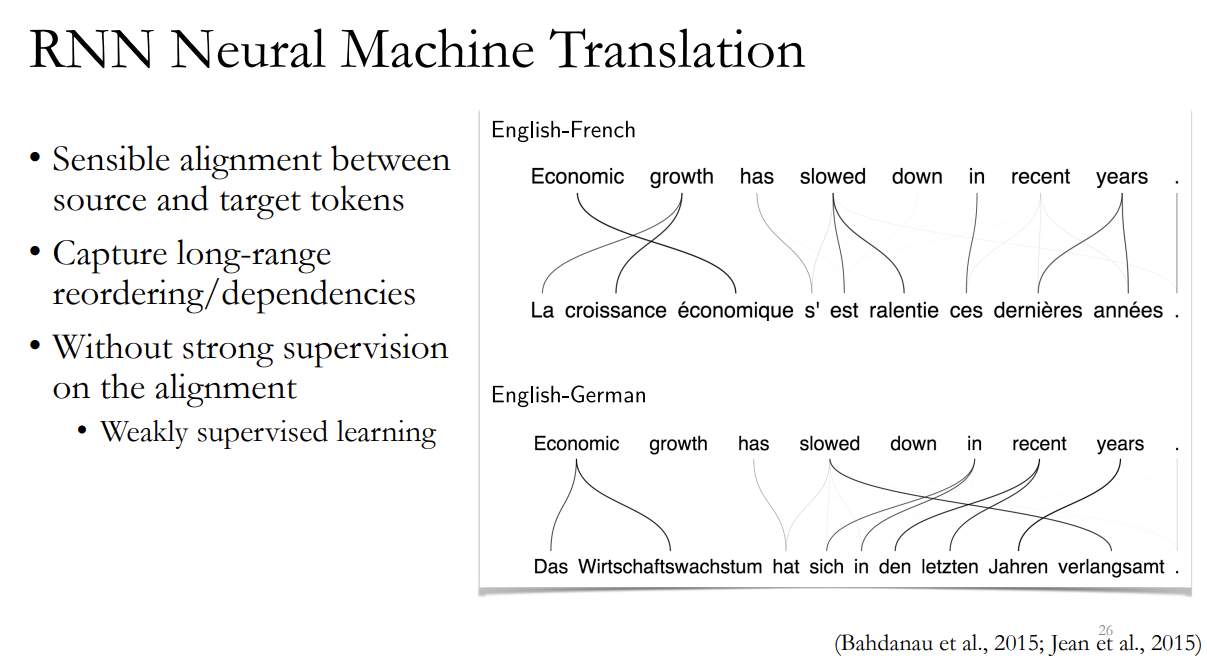
(<lecture4 - machine translation.pdf>의 26쪽 장표를 보면서 설명)
이게 영어에서 불어를 할때는 별로 문제가 안됐습니다.
영어같은 경우 그냥 화이트 스페이스로 세그멘테이션하고 쭉 유니토큰들 하면은 한 밀리언도 안나오거든요 보통 일반적인 코프라보면은. 프렌치도 그렇구요.
근데 이제 절머니나 뭐 우리말도 좀 그런게 있고 뭐 피니쉬 털키쉬같은 이렇게 모폴러지가 좀 리치한 랭귀지들을 보고 컴파운드 월드 들이 있으면은 화이트 스페이스로 짜른다음에 유니크한 애들을 따지면은 절먼같은 경우는 세버럴 밀리언 쉽게 나오고 하거든요.
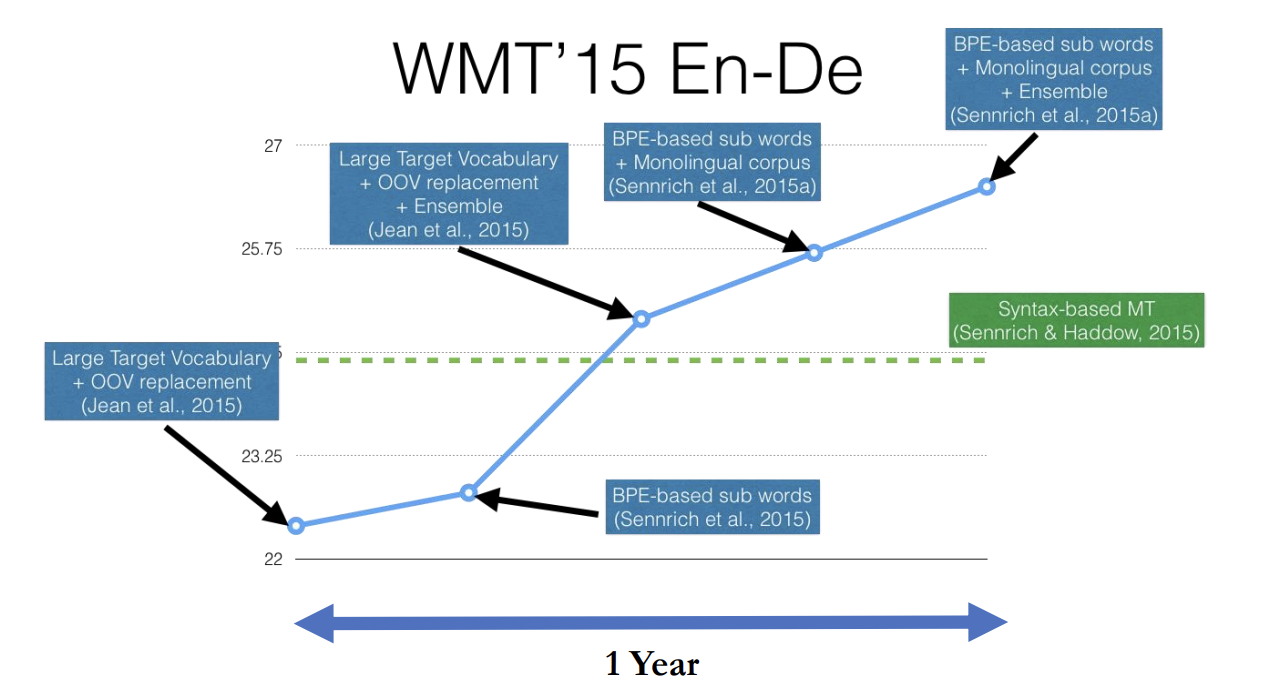
(WMT'15 En-De 장표 보면서 설명 <lecture4 - machine translation.pdf>의 27쪽)
그것 때문에 이제 그걸 해결하기 위해서 저희가 이제 뭐 인포어턴트 샘플링을 써서 한다 뭐 알고리즘적으로 해결했었는데 궁극적으로 간단한 방법은 이 Rico Sennrich라고 지금 애딘버러(University of Edinburgh)에서 교수를 하고 있는 친구가 어 이거 서브월드로 세그멘테이션을 하면 좋겠다 라고 했고, 그 당시에 사람들이 Segmentation을 하기 위해서는 Morphological Analysis 뭐 형태소 분석을 한다든지 아니면은 뭐 이제 Huffman coding같은걸 써서 최대한 이피션트 코드를 찾든지 해야겠다라고 하고 있을때 Rico Sennrich가 그러지 말고 70년대 나온 바이펠인코딩(Biphase Encoding)이라는게 있는데 굉장히 이피시언트하더라 하면서 그 알고리즘을 썼더니 서브월드들이 툭 튀어나오더라구요 한 텐케이 투에니케이면 뭐 절머니며 다 커버할 수 있게. 그래서 그냥 그거 쓰고 있습니다.
comment